VoxForge
VoxForge
We will use the Audacity Sound Editor and Recorder to record your speech to audio files.
1. First, Create a new folder called 'voxforge/test/wav'.
Note: you can use the wav files I created in order to test your acoustic model against a voice that is not you own. My files are here:
|
The testprompts file you created in Step 2 will guide you on what to record. The first column contains the name of the audio file, and
the following words are the words you need to record.
Make sure you are in a quiet environment, your microphone is adjusted correctly, and the recording levels in Audacity are set properly. See Step 3 of the Acoustic Model Creation Tutorial for details on how to do this.
Check your Preferences in Audacity to make sure of the following:
Record you first file by clicking the Record icon in Audacity and saying the words in the first line of your prompts file:
PHONE STEVE YOUNG |
If the track sounds OK then click 'File' on the
Audacity menu, then click 'Export As Wav' and save it as 'test1' in
the 'voxforge/test/wav' folder.
Repeat for all the remaining entries in your testprompts file.
If you want to test the Adapted Acoustic Model you created (i.e. you ran through the Adaptation Tutorial to adapt the VoxForge Speaker Independent Acoustic Model to better recognize your voice), you will need to downsample the test audio you recorded here - as shown below.
The
Acoustic Models you created in the How-to and Tutorial were
used speech audio recorded
with a 48 kHz sampling rate at 16 bits per sample - so no downsampling
is required and you can move to the next step.
The VoxForge Speaker Independent Acoustic Models were trained with audio recorded at 8kHz:16-bits. The audio you just recorded here was recorded at 48kHz:16-bits. Because of this, you need to downsample your speech audio files to 8kHz:16-bits.
1. First, rename your test/wav directory to 'test/wav_input'
2. create a new directory called 'wav' in your test directory.
3. create a file called 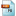 FilesToBeDownsampled in your 'test' directory.
FilesToBeDownsampled in your 'test' directory.
4.
copy the
 downsample.pl
script to your test directory (note that if you download this file,
you need to rename it to 'downsample.pl' - otherwise it will download
as 'downsample_pl.txt').
downsample.pl
script to your test directory (note that if you download this file,
you need to rename it to 'downsample.pl' - otherwise it will download
as 'downsample_pl.txt').
|
Note: the downsample.pl script requires the the SoX sound processing utililiy. To confirm that it is included in your Linux distribution, type 'sox' at a command line, and see if you get an error saying "Failed: Not enough input or output filenames specified". If SoX is not included in your distro, use Yum to install it using the following commands: |
5. run the downsample.pl script as follows (note: you may need to make this script executable - see Cheat Sheet on the Docs page):
| $./downsample.pl FilesToBeDownsampled wav 48000 8000 |
 testspeech.tgz
testspeech.tgz testspeech.zip
testspeech.zip