VoxForge
VoxForge
Da der andere Thread etwas voll und auch etwas unübersichtlich wird, mache ich mal ganz kurz einen neuen auf, bis wir vielleicht eine andere Plattform aufgesetzt haben.
Außerdem wechsele ich auf die Sprache Deutsch.
Ich werde eine Weile weg sein und kündige an dieser Stelle schon mal meinen Kollegen kristian an, der für mich übernehmen wird.
Ziel dieses Threads ist die manuelle Kontrolle des voxforge audio material auf Fehler und eventuell das Tagging zu organisieren.
Zunächst brauchen wir eine Plattform, wo alle deutschen Audiofiles von voxforge namentlich aufgelistet werden. Aus dieser Liste sollte klar ersichtlich sein, welche der files schon gecheckt worden sind,damit wir vermeiden, das wir files doppelt kontrollieren.
Als zweiten Schritt sollten wir uns überlegen, inwieweit wir die Audiofiles taggen wollen bzw nach welchen Kategorien.
Einige Ideen hatten wir schon gebracht.
Noisy/Faulty/Truncated waren einige der Ideen.
Außerdem sollten wir uns überlegen, ob wir noch ein Sytem holen um die Informationen an die Plattform zurück übermitteln. Auf diese Weise könnte jeder, der helfen will, einfach in der Liste nachgucken, welches File noch nicht gecheckt wurde, es kontrollieren und dann das Ergebnis zurückübermitteln.
Die Idee finde ich gut. Grundsätzlich die Frage zur Klärung: Geht es darum die Audio-Dateien zu charakterisieren oder zu qualifizieren?
Will heißen: Soll das Audiomaterial dauerhaft getaggt (charakterisiert) werden, damit die Datenbank im Anschluss z.B. nach allen männlichen Sprechern mit norddeutschem Akzent unter schlechten akustischen Bedingungen (nur ein Beispiel) durchsuchen kann, um das für die eigenen Zwecke zu benutzen? Oder soll "nur mal kurz drübergehört" werden und die Audiodateien dann anhand von (wie auch immer gearteten) Qualitätskriterien in "erfüllt die Kriterien" und "erfüllt die Kriterien nicht" unterteilt werden (also nur zwei sich ausschließende Tags (eher Kategorien), die als Info in die Datenbank müssen). Das hat ja Auswirkungen auf den Aufwand für das System.
Die Kriterien selbst würde ich erstmal grob in vier Aspekte aufgliedern, um daraufhin feingliedriger vorzugehen. Aus dem Bauch heraus würde ich es so gliedern: Der Inhalt wird vom Sprecher unter bestimmten Aufnahmebedingungen aufgenommen und in einer Audiodatei gespeichert. Die vier Aspekte mit beispielhaften (und noch weiter zu vervollständigenden,) möglichst zahlenmäßig erfassbaren Unterpunkten wären - so als Vorschlag:
* Inhalt
* Anzahl gesprochener Worte (10 +/- 4)
* Länge der ÃuÃerung
* Transkription (mit ÃuÃerung übereinstimmend?)
* usw.
* Sprecher
* Dialekt (welcher?)
* Aussprache (weitere Kriterien? Nuscheln, Lispeln?)
* usw.
* Aufnahmebedingung/(-umgebung)
* Rauschen (wie quantifizieren?)
* Lärm (s.o.)
* Ãbersteuert
* usw.
* Audioformat
* Sample Rate
* Bits per Sample
* weitere technische Kriterien
Für eine Charakterisierung oder Qualifizierung des Audiomaterials müssen auf jeden Fall möglichst handfeste Kriterien her, an denen man sich orientieren kann, sonst entsteht evtl. der Eindruck von Willkür. Aber bevor da feste Werte definiert werden sollten wir erstmal die Liste der relevanten Kriterien dort oben befüllen. Aber immer im Hinterkopf, dass es möglichst messbar sein muss.
Mein Senf zum Sonntag.
Viele Grüße
Grilli
Nun habe ich diesen Thread hier (eher durch Zufall) auch gefunden :)
Wie schon gesagt, auch ich halte die Charakterisierung fuer den naechsten wichtigen Schritt - und ich denke auch, wir sollten nicht etwa nur eine Zahl vergeben sondern einzelne Kriterien festlegen, die unabhaengig voneinander moeglichst objektiv abgeprueft werden koennen.
Die hierarchische Gliederung von Grilli finde ich einen sehr guten Ansatz - allerdings denke ich auch, wir sollten es nicht uebertreiben mit den Kriterien sondern - neben der moeglichst einfachen, objektiven Erfassbarkeit - auch die Kosten/Nutzen Relation in Hinblick auf Spracherkennung beachten. Jedes Kriterium macht Arbeit und senkt die Chance, genuegend Mitstreiter zu finden, die auch fuer die Zukunft die Submissions pruefen.
Zu den einzelnen Punkten:
- Inhalt: ich plaediere nach wie vor dafuer, die Transkription des tatsaechlich gesagten als IPA abzulegen. Dafuer muessen wir natuerlich ein Werkzeug bauen, dass die IPA moeglichst automatisiert aus einem Lexikon zusammenbaut, wobei insbesondere bei Woertern, die mehr als eine Aussprache haben, der Benutzer entscheiden muss, welches die tatsaechliche Aussprache des Sprechers in diesem Fall war. Ggf. muss der Benutzer auch neue Aussprachevarianten in das Lexikon einpflegen koennen.
- Sprecher/Dialekt: ich denke, hier muessen wir genau ueberlegen, was wir zulassen wollen und was nicht. Am ehesten koennte ich mir vorstellen, dass wir verschiedene Akzente (bayrisch/sueddeutsch, norddeutsch, saechsisch usw.) hinterlegen wollen - da sollten wir aber eine fixe, kurze Liste definieren sonst wird der Aufwand viel zu gross - es gibt ja hunderte von regionalen Dialekten und Akzenten.
Wirkliche Dialekte wuerde ich ueberhaupt nicht zulassen - wer ein z.B. schwaebisches oder schweizerdeutsches Sprachmodell will, soll dies bitte getrennt bauen - also konkret alles, was ueber leichte Varianten in der Phonologie hinausgeht wuerde ich vorlaeufig einfach rausdefinieren (vielleicht sehen wir ein boolesches Flag "Dialekt" vor um solche Submissions, so es sie denn gibt, zu markieren).
Was wir noch vorsehen sollten, entweder beim Inhalt oder bei den technischen Kriterien sind abgeschnittene Aufnahmen - das passiert leider recht haeufig und muss markiert werden (insbesondere, wenn der Schnitt mitten im Wort passiert und man ihn nicht einfach durch Anpassung der Transkription erfassen kann).
Infrastruktur: Ich frage mich immer noch, ob es sinnvoll waere, fuer diese Aufgabe ein Webinterface mit Datenbank dahinter zu bauen. Das Interface koennte helfen, die Submissions anzuhoeren, nach den Kriterien einzuordnen und insbesondere, die Transkription zu erstellen und - quasi als Nebeneffekt - das Lexikon zu pflegen.
Erstmal vorweg: ich bin der von Binh angekündigte Kollege und werde mal versuchen, in seiner Abwesenheit für ihn das Zepter hochzuhalten.
Aus meiner Sicht ist das grundsätzliche Ziel der Aufbau eines möglichst guten Sprachmodells. Deshalb ist Hauptfokus meiner Meinung nach das Ermitteln von Fehlern und Störfaktoren. Deshalb ist Noisy/Faulty/Truncated sehr wichtig, weil es die grundsätzliche Verwendbarkeit der Quelle einschränkt.
Zu Dialekt: ich glaube nicht, dass man das derzeitige Voxforge-Material dazu benutzen kann, Untermodelle für einzelne deutsche Dialekte zu bauen. Deshalb denke ich, für die meisten Nutzer ist von Interesse, ob ein Dialekt vorhanden ist und ggf. wie stark dieser Dialekt ist. Die einzelnen Dialektarten halte ich für zu schwer einzuordnen und - ohne Verwendung in spezifischen Untermodellen - nicht wichtig genug.
Zu Qualität: tja - wie will man die bestimmen? Das hängt ja auch vom gewünschten Verwendungszweck ab. Da würde ich lieber versuchen, einzelne Aspekte, die der Qualität abträglich sind oder sein können, zu erfassen. Noisy/Truncated eben.
Weitere Tags: sind aus meiner Sicht eher die Kür, würde ich auf jeden Fall optional machen. Wir können auch ein Feld "Anmerkungen" mit freier Angabe vorsehen, wo man dann beliebig "nuschelt", "Ablesestil" oder andere Kommentare eintragen kann. Sortieren kann man darüber dann allerdings nicht mehr.
Ich schlage als Parameter vor: "Hintergrundrauschen/Abweichung vom Transkript/Abgeschnitten/Dialekt"
Als Kodierung entweder "Ja/Nein" oder "nicht vorhanden/leicht/stark"
Alle weiteren möglichen Kriterien sind für mich optional, kann man Felder für vorsehen, würde aber nicht auf deren Ausfüllung bestehen.
Zur Infrastruktur: hat jemand Ideen für eine passende Verwaltungssoftware/-seite?
Ansonsten können wir auch einfach ein Wiki aufsetzen, in dem wir die Liste der Transkriptionen verwalten. Dessen Verwendung dürfte ja den meisten Menschen geläufig sein.
Stimme voellig zu, einfache Kriterien die wir in Hinblick auf eine Generierung des Sprachmodells auswaehlen, ist der richtige Weg.
Zur Infrastruktur: Zumindest ich fuer meinen Teil halte die Metadaten ja in einer Datenbank und lasse dann verschiedene Tools/Skripte darauf los. Bisher habe ich das Lexikon in der Datenbank und nun bin ich dabei, das Schema um die Reviews und Transcripts der Submissions zu erweitern. Nach dem aktuellen Stand der Diskussion habe ich jetzt mal dieses Schema aufgesetzt:
CREATE TABLE submissions (
id integer NOT NULL,
dir character varying(255) NOT NULL,
audiofn character varying(255) NOT NULL,
cfn character varying(255) NOT NULL,
prompt text NOT NULL,
reviewed boolean DEFAULT false NOT NULL,
dialect boolean,
accent boolean,
"noise level" smallint,
distorted boolean,
truncated boolean,
comment character varying(255)
);
die ersten paar Eintraege enthalten einfach die Dateinamen/Verzeichnisnamen aus den Submissions und den Prompt. Danach kommen dann die Review-Daten, das meiste davon simple Booleans. Einzip "Noise Level" habe ich numerisch vorgesehen, dabei wuerde ich
0: low noise, 1: noticable noice, 2: background music/other speakers
als einzig erlaubte Werte vorschlagen.
Ausserdem habe ich eine Tabelle angelegt, die die Transkriptionen aufnehmen soll - wobei ich hier direkt mit meinem Lexikon, das ja auch in der Datenbank sitzt, verknuepfe:
CREATE TABLE transcripts (
id integer NOT NULL,
sid integer,
wid integer,
pid integer
);
sid ist hier die submission-id, wid die word-id (also das geschriebene Wort), pid die pronounciation-id (also welche Aussprache im Audio verwendet wurde, wichtig fuer Woerter mit mehr als einer korrekten Aussprache). Ueber den Primaerschluessel id der Tabelle wird ausserdem die Reihenfolge der Woerter, wie sie im Prompt vorkommen, abgebildet.
Ich will mal sehen, ob ich dazu ein kleines Tool (vielleicht sogar ein Webfrontend) gebastelt bekomme, mit dem man diese Daten dann einfach und schnell ablegen (und natuerlich in die Wavs reinhoeren und sich die IPA-Transcription von MARY/espeak vorlesen lassen) kann. Will aber nichts versprechen.
Egal, was wir technisch verwenden, wir sollten sehen, dass wir die Daten gut maschinell verarbeiten koennen und irgendwie unsere Bemuehungen zusammenfuehren. Ein Wiki ist schoen einfach - aber ich fuerchte es wird schwierig werden, auf die Daten dort gut mit Skripten usw. zuzugreifen - aber vielleicht habe ich da nur zu wenig Erfahrung. Wir koennten alternativ eine zentrale Datenbank verwenden oder auch Spreadsheets und Daten per CSV austauschen und dann ueber Skripte mergen.
Sieht gut aus. Ja, eine Datenbank bietet sicherlich mehr Möglichkeiten der Weiterverarbeitung der Einträge. Allerdings ist es eben auch mehr Aufwand, dazu ein Frontend zu schaffen und zu unterhalten, das andere Nutzer ohne viel Aufwand benutzen können.
Ein paar kleine Anmerkungen noch:
Verstehe ich das richtig, dass die Tabelle transcripts einen Eintrag pro Wort pro submission enthalten soll?
Sehe ich das richtig: bei dem Modell, das du vorschlägst, können Transkriptionen nur Worte/Aussprachen enthalten, die in deinem Lexikon enthalten sind?
Dann bräuchten wir vermutlich einen Mechanismus, der deinem Wörterbuch neue Aussprachen hinzufügen kann, oder einen entsprechenden Platzhalter.
Außerdem möchte ich zu bedenken geben, dass gerade bei Dialekten schnell sehr ungewöhnliche Aussprachen zustande kommen. Ich würde jedenfalls vermeiden wollen, dass zu einem Wort gleich 10 Aussprachen angegeben sind, von denen 8 nur in seltenen (Dialekt-)Fällen überhaupt auftreten können.
Da der andere Thread etwas voll und auch etwas unübersichtlich wird, mache ich mal ganz kurz einen neuen auf, bis wir vielleicht eine andere Plattform aufgesetzt haben.
Außerdem wechsele ich auf die Sprache Deutsch.
Ich werde eine Weile weg sein und kündige an dieser Stelle schon mal meinen Kollegen kristian an, der für mich übernehmen wird.
Ziel dieses Threads ist die manuelle Kontrolle des voxforge audio material auf Fehler und eventuell das Tagging zu organisieren.
Zunächst brauchen wir eine Plattform, wo alle deutschen Audiofiles von voxforge namentlich aufgelistet werden. Aus dieser Liste sollte klar ersichtlich sein, welche der files schon gecheckt worden sind,damit wir vermeiden, das wir files doppelt kontrollieren.
Als zweiten Schritt sollten wir uns überlegen, inwieweit wir die Audiofiles taggen wollen bzw nach welchen Kategorien.
Einige Ideen hatten wir schon gebracht.
Noisy/Faulty/Truncated waren einige der Ideen.
Außerdem sollten wir uns überlegen, ob wir noch ein Sytem holen um die Informationen an die Plattform zurück übermitteln. Auf diese Weise könnte jeder, der helfen will, einfach in der Liste nachgucken, welches File noch nicht gecheckt wurde, es kontrollieren und dann das Ergebnis zurückübermitteln.
Da der andere Thread etwas voll und auch etwas unübersichtlich wird, mache ich mal ganz kurz einen neuen auf, bis wir vielleicht eine andere Plattform aufgesetzt haben.
Außerdem wechsele ich auf die Sprache Deutsch.
Ich werde eine Weile weg sein und kündige an dieser Stelle schon mal meinen Kollegen kristian an, der für mich übernehmen wird.
Ziel dieses Threads ist die manuelle Kontrolle des voxforge audio material auf Fehler und eventuell das Tagging zu organisieren.
Zunächst brauchen wir eine Plattform, wo alle deutschen Audiofiles von voxforge namentlich aufgelistet werden. Aus dieser Liste sollte klar ersichtlich sein, welche der files schon gecheckt worden sind,damit wir vermeiden, das wir files doppelt kontrollieren.
Als zweiten Schritt sollten wir uns überlegen, inwieweit wir die Audiofiles taggen wollen bzw nach welchen Kategorien.
Einige Ideen hatten wir schon gebracht.
Noisy/Faulty/Truncated waren einige der Ideen.
Außerdem sollten wir uns überlegen, ob wir noch ein Sytem holen um die Informationen an die Plattform zurück übermitteln. Auf diese Weise könnte jeder, der helfen will, einfach in der Liste nachgucken, welches File noch nicht gecheckt wurde, es kontrollieren und dann das Ergebnis zurückübermitteln.
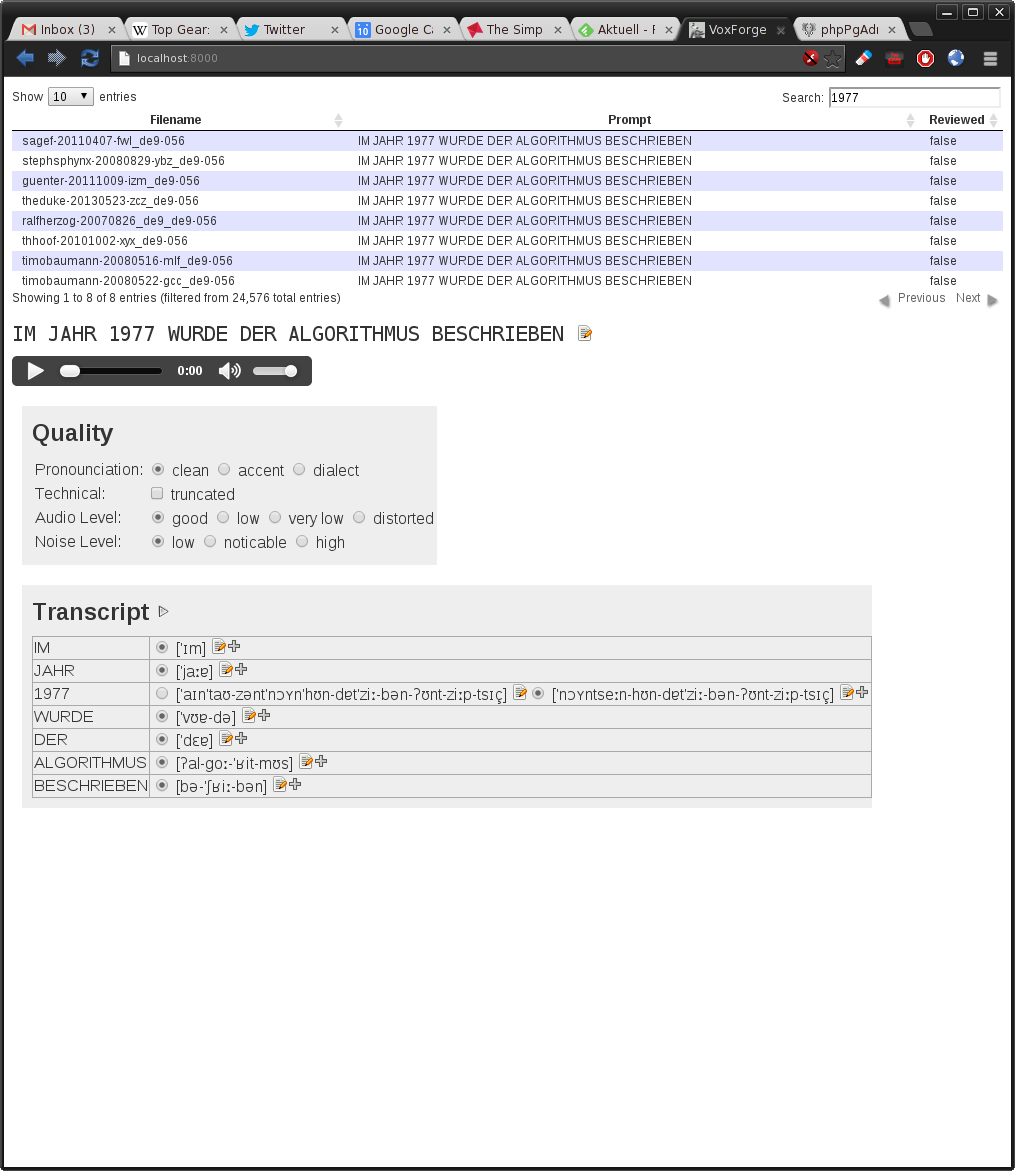
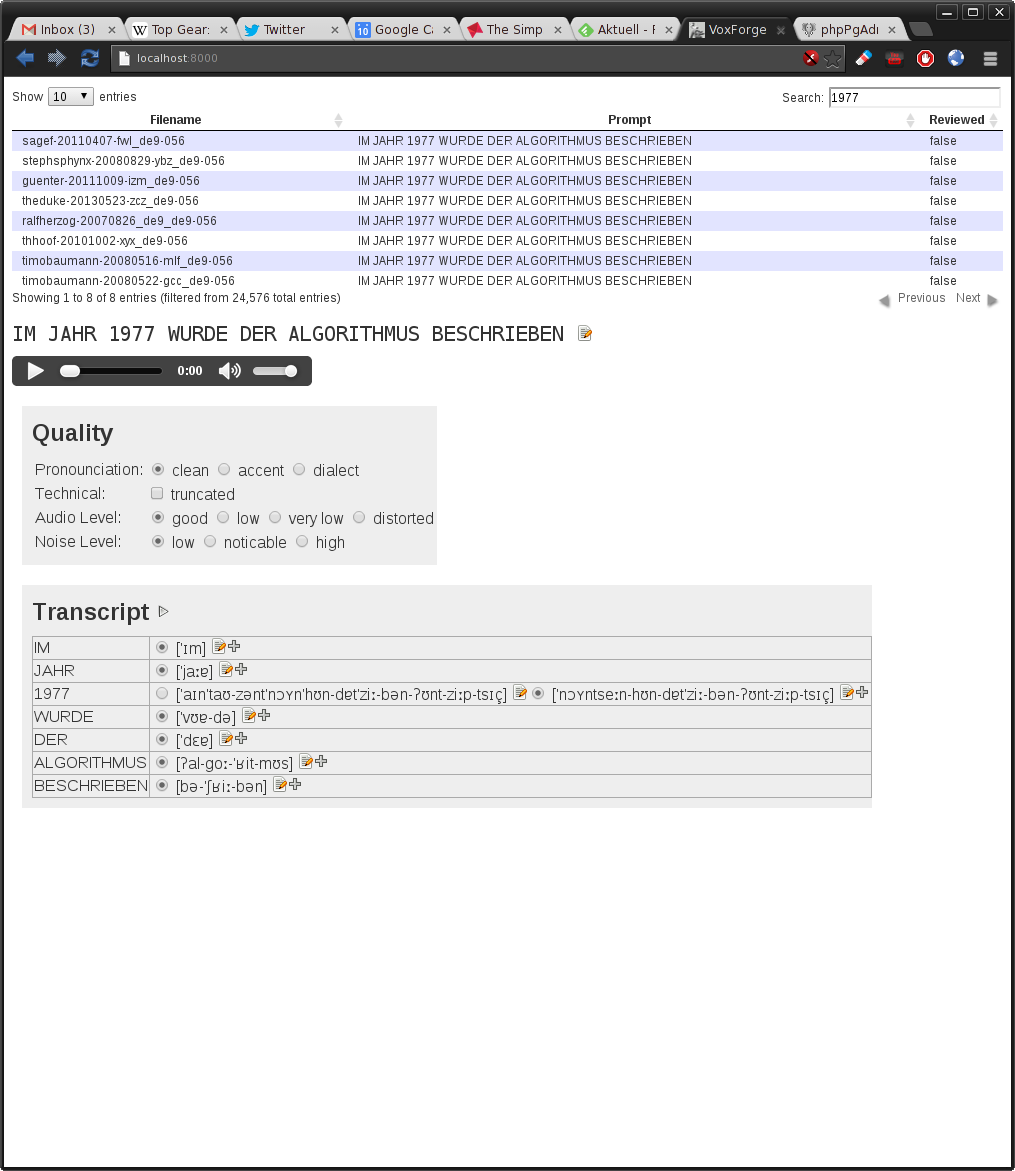
In den letzten Tagen habe ich mit ein wenig jquery und python einen ersten, noch sehr unvollstaendigen prototyp einer Transriptions-Webanwendung zusammengenagelt.
Screenshot:
https://twitter.com/_Gooofy_/status/421594790220685312/photo/1
wie gesagt, alles noch sehr unfertig, aber es verdeutlicht vielleicht ein wenig, wie ich mir so ein Werkzeug vorstellen koennte.
Im Hintergrund sitzt die Datenbank, die neben dem Lexikon nun eben auch Transripts und die Tags fuer jede Submission enthalten kann.
Vorlaeufig bastle ich das Tool nur fuer mich, ich habe aber auf jeden Fall vor, meine Werkzeuge auf github (oder sonstwo) zu veroeffentlichen als freie Software - ich will nur vorher das Datenbankschema halbwegs in trockenen Tuechern haben und sicher sein, dass die Tools fuer mich funktionieren.
Man koennte sich natuerlich vorstellen, das ganze noch viel weiter zu Treiben - sozusagen VoxForge 2.0 ... will mich selber auf so ein Projekt im Moment aber auf keinen Fall committen, dachte nur, ich erwaehne es mal, vielleicht begeistern sich noch mehr Leute hier fuer die Idee? :)
Sehe ich auch so - ein gutes Frontend waere wichtig. Ich fuer mich bastle jetzt erstmal ein kleines Web-Frontend und - wie gesagt - werde den Code dafuer veroeffentlichen. Damit sprechen wir aber sicher keine Massen von Leuten an, wenn sich jeder erstmal einen Webserver samt Datenbank aufsetzen muss :o)
Ich weiss nicht, wie das bei Voxforge aussieht, ob man hier Infrastruktur bereitstellen kann - oder wir sonst jemanden haben, der bereit waere, einen zentralen Server zu betreiben (ich denke selber auch drueber nach, aber mich schreckt der Aufwand und die Verantwortung, die so ein oeffentlicher Server mit sich bringt). Dann koennte man auch Richtung mobile Apps und Gamification nachdenken und so vielleicht mehr Leute ansprechen, um mehr Beitraege zu bekommen - nicht nur zum Lexikon und den Transkriptionen, sondern natuerlich auch Audio-Beitraege - momentan mangelt es ja an allem extrem.
Zum DB-Schema: als ich mir das GUI ueberlegt habe, habe ich manche Optionen weiter zusammengefasst und das Schema entsprechend angepasst, aktuell sieht es so aus:
CREATE TABLE submissions (
id integer NOT NULL,
dir character varying(255) NOT NULL,
audiofn character varying(255) NOT NULL,
cfn character varying(255) NOT NULL,
prompt text NOT NULL,
reviewed boolean DEFAULT false NOT NULL,
noiselevel smallint DEFAULT 0 NOT NULL,
truncated boolean DEFAULT false NOT NULL,
comment character varying(255) NOT NULL,
audiolevel smallint DEFAULT 0 NOT NULL,
pcn smallint DEFAULT 0 NOT NULL
);
COMMENT ON COLUMN submissions.noiselevel IS '0: low noise, 1: noticable noice, 2: background music/other speakers';
COMMENT ON COLUMN submissions.audiolevel IS '0=good, 1=low, 2=very low, 3=distorted';
COMMENT ON COLUMN submissions.pcn IS 'pronounciation: 0=clean, 1=accent, 2=dialect';
> Verstehe ich das richtig, dass die Tabelle transcripts einen Eintrag pro Wort pro submission enthalten soll?
genau - wobei die ID dann die Reihenfolge der Woerter ergibt - man kann also aus dem Transcript dann den Prompt rekonstruieren.
> Sehe ich das richtig: bei dem Modell, das du vorschlägst, können
> Transkriptionen nur Worte/Aussprachen enthalten, die in deinem Lexikon enthalten sind?
ja, genau.
> Dann bräuchten wir vermutlich einen Mechanismus, der deinem
> Wörterbuch neue Aussprachen hinzufügen kann, oder einen
> entsprechenden Platzhalter.
das ist auf jeden Fall im Moment meine Vorgehensweise - fuer meine Zwecke ergibt es im Moment keinen Sinn, Transcripts zu haben, fuer die nicht alle Woerter im Woerterbuch drin sind - ich wuerde also beides parallel pflegen.
> Außerdem möchte ich zu bedenken geben, dass gerade bei Dialekten schnell sehr ungewöhnliche Aussprachen zustande kommen
ich glaube, das Thema hatten wir schon - Dialekte wuerde ich fuer meine Zwecke gar nicht zulassen, deswegen mache ich mir darum wenig Gedanken. Wenn ich tatsaechlich auf eine Submission in Dialekt stosse beim Review, wuerde ich "pcn = 2" setzen und dann waeren mir Prompt und Transkription egal, weil ich so eine Submission eh niemals in mein Modell mit einrechnen wuerde.